這篇來分享將pdf檔案的頁首與頁尾批次刪除!!
有關使用python程式刪除pdf檔案的頁首和頁尾,
google了不少網頁,一直沒辦法找到正確可供執行的程式。
經過嘗試了不少程式碼,再自己改寫後,有了以下的分享:
因為程式碼是以類似圖像的方式讀取pdf檔案,
讀取的pdf文件再透過裁切後(也就是裁切頁首或頁尾後)回寫pdf檔。
了解這個限制後,如果你有興趣閱讀,再往下觀看。
word檔案中的頁首和頁尾,在轉成pdf後,
用pdf編輯器打開,是找不到pdf定義的頁首和頁尾的。
也就是你沒辦法用pdf編輯器一鍵刪除所有原先在word中產生的頁首和頁尾。
很多時候我收到別人的pdf檔,這些檔案很多是用word打好後,再轉成pdf檔。
這些檔案很多都有他們自己加的頁首和頁碼,
但對於彙整資料的人來說,這就很痛苦了。
因為彙整資料的人,要把這些頁首、頁尾的資料先移除,
才能製作自己的頁首與頁尾。
目標文件的pdf檔案為直式與橫式頁面組合而成,
這個pdf是我用word檔加入頁首和頁尾資料做成的示範檔案。
示範檔案下載位置:
https://drive.google.com/file/d/1ihwjwFC2NoG6k62KhuwB6Cek0N876TuR/view?usp=sharing
直式頁面: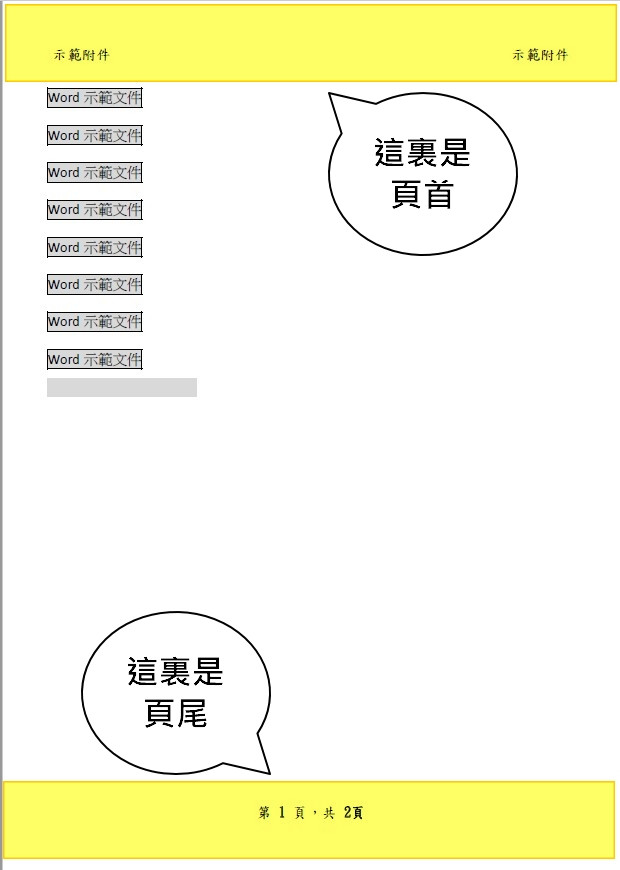
橫式頁面: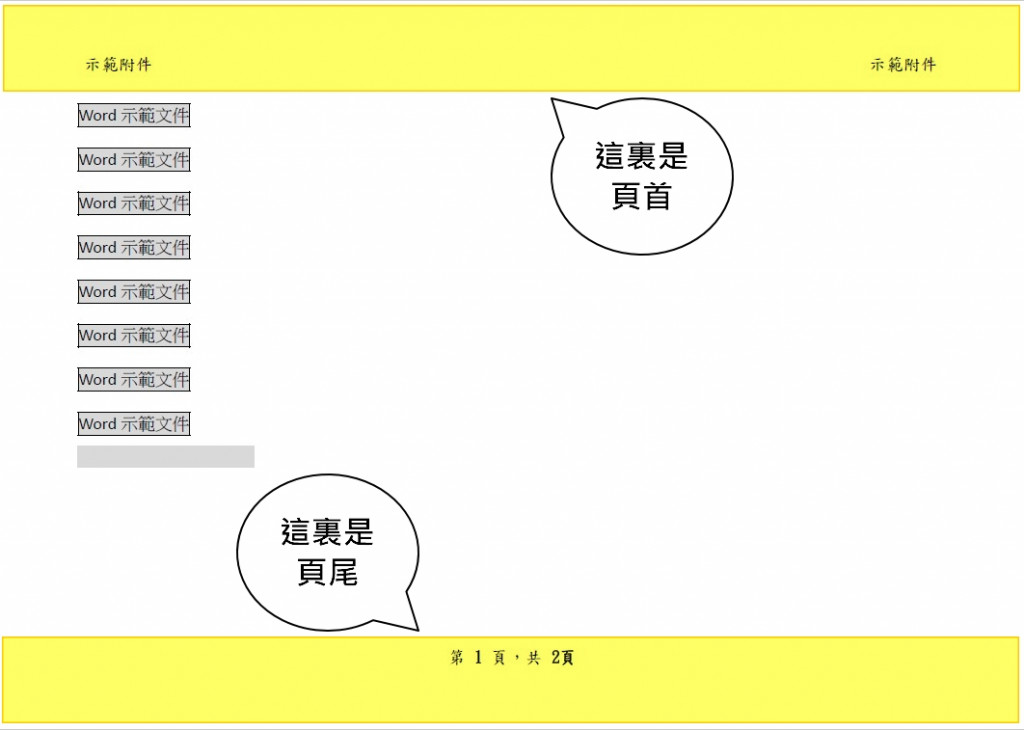
程式碼已考慮直式或橫式頁面的判斷,
這個判斷在PyPDF2中的rotate資料中是有分的,
比如說直式的rotate是0, 文件向右轉90度變成橫式時,則rotate是90,
文件再持續向右轉90度,又變成頭上腳下的直式文件,這時rotate是108。
這次示範的檔案是直式rotate=0和橫式rotate=90的頁面所組合而成的pdf檔案。
接下來就用程式來處理了:
import PyPDF2
def remove_header_or_footer(input_path, output_path):
with open(input_path, 'rb') as file:
reader = PyPDF2.PdfReader(file)
writer = PyPDF2.PdfWriter()
for page_num in range(len(reader.pages)):
page = reader.pages[page_num]
media_box = page.mediabox
header = 35 # 如果不移除頁首,則設為0
footer = 35 # 如果不移除頁尾,則設為0
print(f'PDF檔案第{page_num}頁')
#print(f'PDF檔案第{page}頁') # 這邊的代碼是查看每一頁的文件資訊
print(f"文件旋轉角度:{page.get('/Rotate')}")
print(f'文件左下角座標:{media_box.lower_left}')
print(f'文件左上角座標:{media_box.upper_left}')
print(f'文件右下角座標:{media_box.lower_right}')
print(f'文件右上角座標:{media_box.upper_right}')
print('----------------------------')
# 文件為直式
if page.get('/Rotate') == 0:
# 文件扣除頁首或頁尾的座標定位
media_box.lower_left = (media_box.lower_left[0], media_box.lower_left[1]+footer) # 設定頁面左下角座標
media_box.upper_left = (media_box.upper_left[0], media_box.upper_left[1]-header) # 設定頁面左上角座標
media_box.lower_right = (media_box.lower_right[0], media_box.lower_right[1]+footer) # 設定頁面右下角座標
media_box.upper_right = (media_box.upper_right[0], media_box.upper_right[1]-header) # 設定頁面右上角座標
# 文件為橫式
elif page.get('/Rotate') == 90:
# 旋轉90度的文件扣除頁首或頁尾的座標定位
media_box.lower_left = (media_box.lower_left[0]+header, media_box.lower_left[1]) # 設定頁面左下角座標
media_box.upper_left = (media_box.upper_left[0]+header, media_box.upper_left[1]) # 設定頁面左上角座標
media_box.lower_right = (media_box.lower_right[0]-footer, media_box.lower_right[1]) # 設定頁面右下角座標
media_box.upper_right = (media_box.upper_right[0]-footer, media_box.upper_right[1]) # 設定頁面右上角座標
writer.add_page(page)
with open(output_path, 'wb') as output_file:
writer.write(output_file)
# 指定輸入和輸出檔案路徑
input_file = 'D:\\temp\\test\\Word示範文件_組合.pdf'
output_file = 'D:\\temp\\test\\output.pdf'
# 執行移除頁首或頁尾操作
remove_header_or_footer(input_file, output_file)
print('所有頁面移除頁首或頁尾已完成。')
print('----------------------------')
程式執行結果:
pdf檔處理後的頁面,確實有將頁首和頁尾的資料給刪除了:

仔細看處理後的頁面可以發現上、下都被裁切了!!
雖然文件被裁切,但用pdf編輯器打開後,再以列印式存成pdf檔,
是可以再回復成A4的頁面大小的。
以上就完成這次的分享!!
 mackuo
mackuo

 iThome鐵人賽
iThome鐵人賽